The Null Process
A null process — which takes its name from the concept of null pointers — is what happens when no formal process is put in place. A pointer in computer programming is an object that points to a location in computer memory with meaningful information; it could point to a number, a letter, or even another pointer. A null pointer “points definitively nowhere”. A null pointer is an apt analogy because while it points nowhere, you still have the pointer object which, if used incorrectly, can crash your program.
When people say they don’t want process, what they’re really saying is they don’t want formalized process. There is really no such thing as “no process”. A process is simply the steps it takes to complete a task, so if a task is completed then by definition a process was used. Without formalized process everyone does things their own way, and there is no documentation for how problems are solved. This informal, undocumented process is the “null process”, and, if used incorrectly, the null process can have major implications for a company.
The biggest danger with a null process is that it creates an environment of unspoken expectations. Most of the time, people have expectations about how a task should be completed. In the introductory story, when my coworker was responding to support tickets it became clear that there was an expected way that he should complete the task. His boss intervened to correct what he was doing, yet my coworker and the rest of the team was unaware that there was an expected way to respond to support tickets.
Managing with unspoken expectations is dangerous. How can employees perform to a manager’s standards if they don’t know what’s expected of them? Saying these expectations out loud in a one-off situation means that some people might know what’s expected and others don’t. How can you compare the job performance between employees who know the unspoken processes and those who don’t? Additionally, the more time an employee spends getting their boss to tell them all the unspoken processes for their job, the more likely they are to be successful at the company. But that seems like an inefficient use of the employee and the manager’s time.
A lot of companies end up with null process because they’re afraid of bad process. There is this myth that having no process is liberating and that it frees people up to solve problems the best way possible. While that might be true on a very small, flexible, early-stage team, as a company grows the null process quickly becomes a hindrance. Undocumented process is extremely difficult to teach to new employees, making onboarding and team growth more expensive. The null process can easily transform into unspoken expectations that things are done a certain way, even though the company has not documented the implicitly understood process for completing a task. As Jo Freeman says in her famous essay The Tyranny of Structurelessness, “For everyone to have the opportunity to be involved in a given group and to participate in its activities the structure must be explicit, not implicit”. By relying on implicit processes, companies are creating environments with unspoken expectations that can make it difficult for employees to succeed at their jobs.
Re: Flaw in “random32: update the net random state on interrupt and activity”
You guys know what’s relevant? Reality.
The thing is, I see Spelvin’s rant, and I’ve generally enjoyed our encounters in the past, but I look back at the kinds of security problems we’ve had, and they are the exact reverse of what cryptographers and Spelvin is worried about.
The fact is, nobody ever EVER had any practical issues with our “secure hash function” even back when it was MD5, which is today considered trivially breakable.
Thinking back on it, I don’t think it was even md5. I think it was half-md5, wasn’t it?
So what have people have had real security problems with in our random generators — pseudo or not?
EVERY SINGLE problem I can remember was because some theoretical crypto person said “I can’t guarantee that” and removed real security — or kept it from being merged.
Seriously.
We’ve had absolutely horrendous performance issues due to the so-called “secure” random number thing blocking. End result: people didn’t use it.
We’ve had absolutely garbage fast random numbers because the crypto people don’t think performance matters, so the people who do think it matters just roill their own.
We’ve had “random” numbers that weren’t, because
random.cwanted to use only use inputs it can analyze and as a result didn’t use any input at all, and every single embedded device ended up having the exact same state (this ends up being intertwined with the latency thing).We’ve had years of the
drivers/char/random.cnot getting fixed because Ted listens too much to the “serious crypto” guys, with the end result that I then have to step in and say “f*ck that, we’re doing this RIGHT”.And RIGHT means caring about reality, not theory.
So instead of asking “why is the slow path relevant”, the question should be "why is some theoretical BS relevant", when history says it has never ever mattered.
Our random number generation needs to be practical.
When Spelvin and Marc complain about us now taking the fastpool data and adding it to the prandom pool and “exposing” it, they are full of shit. That fastpool data gets whitened so much by two layers of further mixing, that there is no way you’ll ever see any sign of us taking one word of it for other things.
I want to hear practical attacks against this whole “let’s mix in the instruction pointer and the cycle counter into both the 'serious' random number generator and the prandom one”.
Because I don’t think they exist. And I think it’s actively dangerous to continue on the path of thinking that stable and “serious” algorithms that can be analyzed are better than the one that end up depending on random hardware details.
I really think kernel random people need to stop this whole “in theory” garbage, and embrace the “let’s try to mix in small non-predictable things in various places to actively make it hard to analyze this”.
Because at some point, “security by obscurity” is actually better than “analyze this”.
And we have decades of history to back this up. Stop with the crazy “let’s only use very expensive stuff has been analyzed”.
It’s actively detrimental.
It’s detrimental to performance, but it’s also detrimental to real security.
And stop dismissing performance as “who cares”. Because it’s just feeding into this bad loop.
Is it reasonable to build applications (not games) using a component-entity-system architecture?
More traditional OOP approaches can be really strong when you have a firm grasp of the design requirements upfront but not the implementation requirements. Whether through a flatter multiple interface approach or a more nested hierarchical ABC approach, it tends to cement the design and make it more difficult to change while making the implementation easier and safer to change. There’s always a need for instability in any product that goes past a single version, so OOP approaches tend to skew stability (difficulty of change and lack of reasons for change) towards the design level, and instability (ease of change and reasons for change) to the implementation level.
However, against evolving user-end requirements, both design and implementation may need to frequently change. You might find something weird like a strong user-end need for the analogical creature that needs to be both plant and animal at the same time, completely invalidating the entire conceptual model you built. Normal object-oriented approaches don’t protect you here, and can sometimes make such unanticipated, concept-breaking changes even harder. When very performance-critical areas are involved, the reasons for design changes further multiply.
Combining multiple, granular interfaces to form the conforming interface of an object can help a lot in stabilizing client code, but it doesn’t help in stabilizing the subtypes which could sometimes dwarf the number of client dependencies. You can have one interface being used by only part of your system, for example, but with a thousand different subtypes implementing that interface. In that case, maintaining the complex subtypes (complex because they have so many disparate interface responsibilities to fulfill) can become the nightmare rather than the code using them through an interface. OOP tends to transfer complexity to the object level, while ECS transfers it to the client (“systems”) level, and that can be ideal when there are very few systems but a whole bunch of conforming "objects" (“entities”).
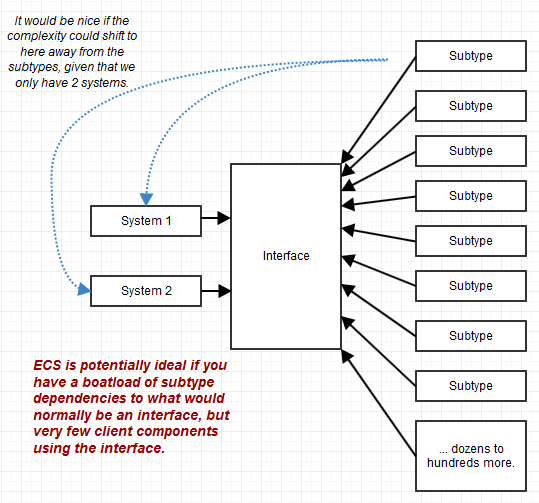
A class also owns its data privately, and thus can maintain invariants all on its own. Nevertheless, there are “coarse” invariants that can actually still be hard to maintain when objects interact with each other. For a complex system as a whole to be in a valid state often needs to consider a complex graph of objects, even if their individual invariants are properly maintained. Traditional OOP-style approaches can help with maintaining granular invariants, but can actually make it difficult to maintain broad, coarse invariants if the objects focus on teeny facets of the system.
That’s where these kinds of lego-block-building ECS approaches or variants can be so helpful. Also with systems being coarser in design than the usual object, it becomes easier to maintain those kinds of coarse invariants at the bird’s-eye view of the system. A lot of teeny object interactions turn into one big system focusing on one broad task instead of teeny little objects focusing on teeny little tasks with a dependency graph that would cover a kilometer of paper.
Data on the Outside vs. Data on the Inside
Messages may contain data extracted from the local service’s database. The sending application logic may look in its belly to extract that data from its database. By the time the message leaves the service, that data will be unlocked.
The destination service sees the message; the data on the sender’s service may be changed by subsequent transactions. It is no longer known to be the same as it was when the message was sent. The contents of a message are always from the past, never from now.
There is no simultaneity at a distance. Similar to the speed of light bounding information, by the time you see a distant object, it may have changed. Likewise, by the time you see a message, the data may have changed.
Services, transactions, and locks bound simultaneity:
Inside a transaction, things are simultaneous.
Simultaneity exists only inside a transaction.
Simultaneity exists only inside a service.
All data seen from a distant service is from the “past”. By the time you see data from a distant service, it has been unlocked and may change. Each service has its own perspective. Its inside data provides its framework of “now”. Its outside data provides its framework of the “past”. My inside is not your inside, just as my outside is not your outside.
Using services rather than a single centralized database is like going from Newton’s physics to Einstein’s physics:
Newton’s time marched forward uniformly with instant knowledge at a distance.
Before services, distributed computing strove to make many systems look like one, with RPC (remote procedure call), two-phase commit, etc.
In Einstein’s universe, everything is relative to one’s perspective.
Within each service, there is a “now” inside, and the “past” arriving in messages.
The problem with C
On the surface, C and C++ cater to the same use cases: high performance, deterministic, native but portable code for the widest range of hardware and applications.
But C is proudly a low-level language. A nicer assembly.
From day one, C++ had magic. Dark witchcraft: destructors. Suddenly the compiler was doing things on its own. It also had type inference very early on, but the developers of the mid-80s were not quite ready for that and Bjarne Stroustrup was pressured into removing
auto, until it was added back to C++11.From then, C++ got more and more tools to build abstractions. I don’t think it would be fair to say that C++ is a low-level or high-level language. It’s both, by design. But building high-level abstractions while not sacrificing performance is hard. C++ then needed tools to achieve that:
constexpr, move semantics, templates, and an ever-growing standard library.Fundamentally I think C trusts developers while C++ trusts compilers. This is a massive difference that sharing the same native types or syntax for while loop cannot hide.
C++ developers blame C for all their lost limbs, while C developers probably think C++ is batshit crazy. I imagine that is a fair perspective if you look at C++ through a C lense. C++ is pretty wild as a superset of C. A seasoned C person looking at C++ expecting familiarity in C++ will not find it. C++ is not C. This is enough to feed flamewars for generations.
If you are a C developer, I imagine you see C as a neat programming language. But for the rest of us, C is something else.
C is the universal, cross-language glue that ties it all together.
For C++ users, C is exactly its API. And with that in mind, the value of C is in its simplicity. Remember that the subset of C that C++ cares about is the subset that appears in interfaces, in header files. We care about declarations. Not definitions. C++ wants to call functions in C libraries (or Python, Fortran, Rust, D, Java, etc, in all cases C can be used at the interface boundary).
In that light, C is an interface definition language. The more bells and whistles are added to C, the harder it gets to define interfaces. And the less likely it is that these interfaces will remain stable over time.
A Quick Primer on Robert “Uncle Bob” Martin
It’s easy and comforting to blame individual programmers for bad code. But if you’re actually interested in making software better, then you should realize that being careful and using tools that prevent mistakes are not mutually exclusive — using tools that prevent mistakes frees up your mental energy to focus on preventing higher level errors, rather than worrying about null pointer exceptions and double-frees.
Tech Bullshit Explained: Uncle Bob
But in short back in the nascent days of software, organizations weren’t sure how to manage software projects. So people invented a whole bunch of weird pyramid scams for selling books, tools, and training. Oops I mean new “software development methodologies” . Like one called Extreme Programming. I’m not joking.
There were so many of these cults that in 2001 seventeen white dudes decided to meet up at a ski resort to distill them into one big cult. They called it The Manifesto for Agile Software Development.
They had to make Software Craftsmanship because Agile became too much about project management and not about code. This made software devs sad because they hate it when things aren’t about them. Uncle Bob and others thought too much code sucked. And people weren’t paying enough attention to writing code that didn’t suck. They decided the solution was to LARP as medieval craftspeople. And pretend they were making beautiful woodcarvings instead of pop up windows on websites.
On Browser Tabs
Keeping these tabs open is a form of externalized working memory. Jumping back in should feel akin to the last time a user was immersed in that window. At some point though, the number of tabs begins to toe the line between externalized memory and information hoarding. The desire to keep tabs open for too long with no end-state is similar to physical hoarding.
I know there are some solutions that “save” tabs. These extensions are designed to snapshot a window and store it. I’ve used these before and find them useful although they still feel very unorganized and stiff. There’s also a significant amount of cognitive load to readjust to all of the information. These solutions address the problem directly but the tab issue is a manifestation of a more “core” issue around organizing goal-driven information consumption. Unpacking the relationship between tabs and cognition may be a step in the right direction.
The tab is also just a wrapper around what’s really important: the content inside it. Maybe it’s a paragraph, a piece of code, or a video vs. everything else that comes with the site. Part of the solution here is rethinking the way we organize the information that we think is relevant on a given site.