The culture war in open source is on
People often talk about open source as a commons, but if you go back and read Elinor Ostrom's studies on pre-digital practices of commoning around the world, you’ll find that there are some important things missing. (She didn’t identify her work with feminism, but she is still the first woman to have won the Nobel in economics.) Ostrom recognized boundary-making as an essential practice for commoners — defining who is a member and what purpose the commons serves, whether economic, social, or otherwise. She also found that a healthy commons depends on participants having a voice in changing its rules and norms, which is a far cry from the dictatorships-for-life that tend to rule open source. If open source listened better to the legacy of commoning before it, projects wouldn’t just choose a license, they would start by adopting a governance structure and finding a place to manage funds. They would plan for economic and ethical self-determination — autonomy was another principle Ostrom emphasized — rather than outsourcing those matters to corporate whims.
Anyway, it is only natural that open source contributors should want to hack the process, not just the software they write. For all that open source has achieved, there is so much more that it hasn’t. “The year of the Linux desktop” has turned from an expectation to a joke, unless you count Google’s Android and Chromebooks. The open Web has closed shut. Surveillance-powered corporate platforms have accumulated power because of, not despite, open source. And the staggering homogeneity that still persists among open source developers testifies to the talent and life experience that their projects are missing.
If the early architects of open source feel threatened by a new generation demanding more, that is probably a sign of progress.
Burn the glitch?
In his germinal book Archaeogaming An Introduction to Archaeology In and Of Video Games, Andrew Reinhard devotes an entire section of Chapter 3 (“Video Games as Archaeological Sites”) to exploring the idea that glitches are archaeological artefacts. As glitches can arise from errors in code, he compares them to the misfired pots that archaeologists discover during excavation (2018, 152). I would also compare them to the fingerprints that are found on pottery and other materials. Similar to glitches, these fingerprints provide more information about the production process and the labour involved. Further parallels can be drawn in that fingerprints can be intentional or unintentional, and are not necessarily imprinted by the original creator of the object (Králík and Nejman 2001, 11), as ceramics may have been produced in workshops resulting in numerous people working on and interacting with the “beta” version of the pot before it was fired. Glitches and other perceived imperfections, like preserved fingerprints, also have an affective aspect in that they manifest the otherwise implicit human labour that went into the creation of analogue or digital craft. The glitch as queer agent invites player reflection on the process of the game’s creation, which otherwise could be obscured by its marketing and consumption as commercial product.
It’s not what programming languages do, it’s what they shepherd you to
Shepherding: An invisible property of a progamming language and its ecosystem that drives people into solving problems in ways that are natural for the programming language itself rather than ways that are considered “better” in some sense. These may include things like long term maintainability, readability and performance.
Dealing with software collapse
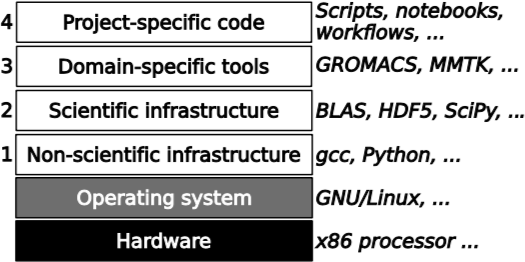 Fig. 1. A typical scientific software stack
Fig. 1. A typical scientific software stackLet’s make this more concrete by considering the layers of a typical scientific software stack as shown in Fig. 1. Its ultimate foundation (in black) is the computer hardware that does all the computations. The gray layer right above it, the operating system, performs basic services and isolates the upper layers of the stack from hardware minutiae. So much, in fact, that most software developers consider the operating system, rather than the hardware, the foundation to keep in mind for their artefacts. What computational scientists are most concerned with are the four numbered white layers in Fig. 1, and that is what I will concentrate on. However, it happens occasionally that software collapse is caused by the two foundation layers, as in the case of the Pentium FDIV bug that made a lot of noise in 1994.
Layer 1 contains infrastructure software that is not specific to scientific computing. This includes compilers and interpreters, libraries for data management, but also higher-level tools such as text editors and Web browsers. For the typical computational scientist, this is software that they obtain from the wider non-scientific software market. They can choose which software to use, but they do not have much impact on its development.
Layer 2 is infrastructure created specifically for scientific computing, but not for any particular application domain. Here we find widely used mathematical libraries such as BLAS, LAPACK or SciPy, scientific data management tools such as HDF5, visualization libraries such as VTK, infrastructure for high-performance computing such as MPI, and many more. These software packages are often developed by software professionals as well, but in contrast to layer 1 software, computational scientists are the specific client group the software is written for, which gives them more influence on its evolution.
Layer 3 contains domain-specific research software. These are tools and libraries that implement models and methods which are developed and used by communities ranging in size from a single research lab to thousands of researchers. The examples I have quoted in Fig. 1 are from my own field of research, biomolecular simulation, so unless that is your field as well, you have probably never heard of them. Often the developers are simply a subset of the user community, i.e. scientists who do software development on the side. Larger communities may have research software engineers who have a science background but specialize in software development. In either case, developers work in very close contact with their users, who provide essential feedback not only on the quality of the software, but also on the directions that future developments should take.
Finally, layer 4 contains the software written by scientists for a specific research project. It can take various forms including scripts, notebooks, and workflows, but also special-purpose libraries and utilities. It is becoming more and more common to publish this software in the interest of transparency and reproducibility, but for inspection rather than for reuse by other scientists.
Software in any of these four layers depends on software from the same or lower layers, and is therefore at risk of collapse if one of its direct or indirect dependencies introduces changes that break backwards compatibility. There are three main causes for such changes. What comes to mind first is a development decision to give up backwards compatibility in exchange for the freedom to improve the software’s interface. But accidental breakage is probably more common in practice, in particular when interfaces are defined ambiguously and/or insufficiently documented. Bugs can also cause accidental breakage, but since they will usually be fixed upon discovery, they are less of an issue in the long run. Finally, a dependency may simply disappear together with the server that hosted it. That risk is highest for software distributed via a lab’s home page, rather than via code hosting sites such as GitHub, but code hosting sites aren’t eternal either — anyone remember Google Code?
Consider the time scale of change in your own project. Do you develop software that implements well-known and trusted methods for use by a large number of researchers? In that case, your software will evolve very slowly, fulfilling the same role for decades. At the other extreme, if your software is developed as part of research in a fast-moving field like machine learning or bioinformatics, it will evolve rapidly, and last year’s release may be of interest only for the history of science. As a rule of thumb, the time scale of layer-4 software is the duration of the project it serves plus the length of time you expect your computations to remain reproducible. For layer-3 software, it’s the time scale of methodological advance in its research domain that matters. Check for example How old are the methodological papers that you tend to cite. Infrastructure software, i.e. layers 1 and 2, can fulfill its role only if it is more conservative than anything that depends on it, so its time scale of change is defined by its intended application domains.
Next, you must estimate the time scale of change of your dependencies. For layer-3 dependencies, that should be rather straightforward, as they are likely to evolve in the same research community as yourself, and thus evolve on similar time scales as your own work. For infrastructure software, the task is more difficult. The fact that you are considering to adopt package X as a dependency does not mean that the developers of X have your needs in mind. So you have to look at the past evolution of X, and perhaps at the time scales of the major clients of X, to get an idea of what to expect for the future. For young projects, there isn’t much past to study, so you should estimate their time scale by their age.
Once you have all these time scale estimates, you can identify the most risky dependencies: those whose time scales of change are faster than your own. If you go for strategy number 3, i.e. adapting your code rapidly to changes in the dependencies, then you might have to invest a lot of effort into catching up with those fast-moving projects.
Of course, change doesn’t mean breaking change. Your dependencies may well evolve at a rapid pace by growing to implement more functionality, while being careful not to break backward compatibility. It’s therefore also important to know the projects' policies, and the means at their disposal to actually implement them. But even if a project’s policy assigns a high priority to preserve backward compatibility, a fast pace of change is still a warning sign because all change entails a risk of making your software collapse by accident. Again, the best estimate is obtained by looking at the project’s track record.
Speaking of policies, you should also think about your own, and ideally write it down clearly as part of your documentation. You can make your clients' life even easier by adding your estimate of your project’s time scale of change.
Spotify’s failed #SquadGoals
Without a single engineering manager responsible for the engineers on a team, the product manager lacked an equivalent peer — the mini-CTO to their mini-CEO role. There was no single person accountable for the engineering team’s delivery or who could negotiate prioritization of work at an equivalent level of responsibility.
When disagreements within the engineering team arose, the product manager needed to negotiate with all of the engineers on the team. If the engineers could not reach a consensus, the product manager needed to escalate to as many engineering managers as there were engineering specializations within the team. A team with backend, Web app, and mobile app engineers would have at least 3 engineering managers who might need to get involved. If those engineering managers could not reach a consensus, a single team’s issue would have to escalate to the department’s engineering director.
When a company is small, teams have to do a wide range of work to deliver and have to shift initiatives frequently. As a company grows from startup to scale-up, duplicated functions across teams move to new teams dedicated to increasing organization efficiency by reducing duplication. With more teams, the need for a team to shift initiative decreases in frequency. Both of these changes allow for teams to think more deeply and long term about the problems they are scoped to solve. Faster iteration, however, is not guaranteed. Every responsibility a team cedes to increase its focus becomes a new cross-team dependency.
Spotify did not define a common process for cross-team collaboration. Allowing every team to have a unique way of working meant each team needed a unique way of engagement when collaborating. Overall organization productivity suffered.
Autonomy requires alignment. Company priorities must be defined by leadership. Autonomy does not mean teams get to do whatever they want.
Processes for cross-team collaboration must be defined. Autonomy does not mean leaving teams to self-organize every problem.
How success is measured must be defined by leadership so people can effectively negotiate cross-team dependency prioritization.
Autonomy requires accountability. Product management is accountable for value. The team is accountable for delivering “done” increments. Mature teams can justify their independence with their ability to articulate business value, risk, learning, and the next optimal move.
Collaboration is a skill that requires knowledge and practice. Managers should not assume people have an existing comprehension of Agile practices.
When a company becomes big enough, teams will need dedicated support to guide planning within the team and structure collaboration between teams. Program management can be accountable for the planning process. Dedicated program managers enable teams in a manner similar to how dedicated product managers and engineering managers do with their respective competencies.
When Agile Scrum introduced new meanings to a bunch of words like burn-down and sprint, it did so because it introduced new concepts that needed names. Spotify introduced the vocabulary of missions, tribes, squads, guilds, and chapter leads for describing its way of working. It gave the illusion it had created something worthy of needing to learn unusual word choices. However, if we remove the unnecessary synonyms from the ideas, the Spotify model is revealed as a collection of cross-functional teams with too much autonomy and a poor management structure. Don’t fall for it. Had Spotify referred to these ideas by their original names, perhaps it could have evaluated them more fairly when they failed instead of having to confront changing its cultural identity simply to find internal processes that worked well.
Most businesses can only sustain a few areas of innovation. Internal process rarely is a primary area of innovation that differentiates a company in the marketplace. Studying the past allows businesses to pick better areas for innovation.