Pour mon usage personnel, par exemple télécharger des sites ou des BDs pour les lire hors ligne sur une liseuse, ou pour rendre services à des amis en extrayant des données structurées, j’ai souvent besoin d’écrire des scraper pour des sites web.
Il serait généralement possible d’utiliser un outil de scraping générique et de le paramétrer, ou de télécharger l’intégralité du site avec un outil comme HTTrack puis de traiter les fichiers en local, mais un scraper maison est souvent plus efficace car on peut facilement ne télécharger que les contenu qui nous intéressent, et extraire à la volée les données dont on a besoin.
Une fois qu’on a une base de code qui fonctionne et qu’on maîtrise bien, le modifier pour un nouveau usage se fait facilement. C’est un des cas où copier / coller un existant et le rééditer pour chaque nouveau besoin est plus efficace que d’essayer d’avoir une solution générique qu’on aurait “seulement” à configurer.
Cet article se propose de vous guider pas à pas jusqu’à avoir une première version complète, dans l’idée de vous rendre autonome.
Par ailleurs, la conception d’un scraper permet de creuser quelques sujets intéressantes, naturellement un peu de HTML et de HTTP mais aussi de stockage de données.
Avertissement : de nombreux sites indiquent dans leur conditions d’utilisation qu’il n’est pas autorisé de les scraper. Je ne sais pas si ces messages ont une valeur légale, mais cet article n’est pas un encouragement à scraper ces sites.
Le scraper à développer
Je vais ici développer un scraper qui fait de l’archivage de site web. Son objectif est d’obtenir une copie locale d’un site qui soit navigable en ouvrant les fichiers dans un navigateur.
Pour les fichiers et le parcours du site, le scraper parcourra le HTML généré côté serveur sans exécuter le JavaScript, et ne sera donc pas compatible avec des sites générés côté client.
Il est possible d’écrire en Ruby des scraper qui savent exécuter du JavaScript, par exemple avec des outils comme Puppeteer Ruby qui peut piloter une instance de Chrome, mais cela demande plus de travail et j’en ai rarement eu besoin quand j’ai fais du scraping, je ne traiterai donc pas ce sujet ici.
Comme l’objectif est d’obtenir un code facile à modifier plutôt que facile à étendre, le code sera placé dans un fichier unique est dans un style procédural, c’est-à-dire en évitant de structurer le code à l’aide de classe mais en utilisant uniquement des méthodes.
Télécharger une seule page
Pour commencer je vais télécharger uniquement le contenu HTML d’une page dont l’adresse est spécifiée dans le code.
Pour le téléchargement j’utilise la classe Net::HTTP fournie par la bibliothèque standard Ruby.
Certes il existe de nombreuses librairies externes fournissant des fonctionnalités plus évoluées et/ou des API plus simple, mais pour les besoins de scraping Net::HTTP suffit généralement, et il intéressant de la connaître un peu car elle est utilisée par défaut par de nombreuses librairies.
Pour un scraper minimal, la seule méthode à connaître est Net::HTTP#get qui fait une requête GET à partir d’une URL et qui renvoie le contenu.
La classe URI::HTTP de la bibliothèque standard Ruby implémente les différents standards mais elle est assez stricte.
Cela signifie qu’elle n’apprécie pas toujours qu’on prenne des liberté avec les standard.
Les navigateurs sont eux plutôt tolérants, et par conséquent les sites ne sont pas incités à suivre les standard au pied de la lettre.
Cela signifie que pour du scraper, mieux un parser d’URL tolérant, et pour cela je vais utiliser la bibliothèque Addressable.
Voici donc le code :
#!/usr/bin/env ruby
require 'net/http'
require 'addressable'
INITIAL_URL = 'http://example.com'
puts "Télécharge [#{INITIAL_URL}]"
parsed_url = Addressable::URI.parse(main_url)
response = Net::HTTP.get(parsed_url)
IO.write('index.html', response)L’exécution du script devrait créer en local un fichier index.html qui contient le source de la page.
La page téléchargée à example.com n’utilisant ni image ni CSS externe, la version locale est auto-portante (en tous cas au moment où j’écris cet article).
Configurabilité ? Non, merci !
Pour un outil classique, la deuxième étape serait de rendre le script configurable, en permettant par exemple de lui passer l’URL d’entrée du site ou le répertoire cible en paramètre.
Mais rappelez vous que mon objectif n’est pas d’avoir un script configurable mais un script facilement éditable. Avoir une URL en dur dans une constante en début de fichier fait donc très bien l’affaire.
Télécharger une page et ses dépendances
À la place, la deuxième étape va consister à télécharger une page et ses dépendances externes : images, feuilles de style et fichiers JavaScript.
Je vais prendre pour cible le site du magazine ACM Queue qui est un magazine publiant des articles d’ingénierie logicielle.
URLS et noms de fichiers
Mais d’abord il me faut parler des URLs et des noms de fichiers.
Il y a très longtemps, les URLs ne pouvaient quasiment utiliser que des caractères alphanumériques. Les dinosaures régnaient sur le monde et la vie était simple.
Désormais on peut avoir des URLs avec des loutres comme https://emojipedia.org/emoji/🦦/.
Dans un scraper qui archive un site chaque contenu est sauvegardé. Si cette sauvegarde est faite dans une base de données classique, comme par exemple une base SQL, vous pouvez stocker les URLs dans un champ de texte, même si elles contiennent des loutres.
Si la base de donnée utilisée par le stockage est un système de fichier, les choses peuvent être moins simple.
Les systèmes d’exploitation peuvent être peu contraignants sur les formats de noms de fichiers (par exemple avec le système de fichiers ext4 souvent utilisé sous Linux tous les caractères sont autorisés à part NULL et /).
Mais en pratique vous n’avez peut-être pas envie d’avoir sur votre disque dur ü͉̞͖͇̥̫̊͞n̢̟͖̺̗̥̱̬̅̾̿ͅ ̬̑̀ f͆ͧ҉̺̪͚̩̭̭̙i̵̤̟͚̳̠̟̣̬̽̊̑c͎̳̘̟̼͊ͤ͠h̫̫̎̒ͯͪ͘ͅi̦͉̞̩̠̫̲̅ͥ̀͠e̵͚̘̒r̹̝͔̪͉̙̒͑ͦ͞ ͉̲͓̘͌͢ͅq̶͈̺͈̫̜͎͉͉̌͊̍̚u̫̤͖̼̮̝͐ͤ͢ḭ̱͕͔̮̗̲̂͂̇̽̕ ̈́͌҉̭͎̪ͅṣ̨͕͇͕̯̗̗̭͙̭̳̼̖̄̐͋͂͡'̴̩̥̭̤̫̖̈̐a̳̙͍̯ͩ̆̽͛́p̝̮̦̹͇̥ͪ͗̂͟p͈͙͓̻ͤͭ͟e̪͆ͬ̆ͭ̕ͅl͈̩̜̓ͫ̕l̴̞̟̼͕͙̮̤̺̊̓ͣe̷͇̰͙͒̔͛̚ ̭̻̰͇̖̆͡c̨̬̖̥̖̽ͪ̈́o̢͈̲̭͈̟̫̭̒̂̾ͤm̭͉̩͔͎̼̳͖ͧ͡m̴͎̙̳̟̖͆̔ę͇̲̻̠͎̊͂ͬ̊ͅ ̨͕͔͕̹̼̓̒̃�̛͎̜͇̹̻̰͚̹ͧͩ�̭̗͓͖̤̖̬ͫ̆̑͞a̡̪͍̪̍
Cela signifie qu’il faut trouver une opération permettant de transformer les URLs en nom de fichier acceptables.
On pourrait vouloir supprimer les caractères qu’on veut éviter en ne conservant que les caractères compatibles. C’est ce qui est est fait dans certains CMS pour transformer des noms de fichiers en URLs.
L’inconvénient de cette méthode est qu’elle supprime des informations (les caractères non acceptables), et qu’en faisait ça deux URLs différentes peuvent être transformées en un nom de fichier identique.
https://emojipedia.org/emoji/🐰/ et https://emojipedia.org/emoji/🐈/ auraient ainsi le même nom de fichier.
L’opération de transformation doit donc avoir les caractéristiques suivantes :
-
une même URL doit toujours about au même nom de fichier (pour éviter d’avoir des doublons)
-
un nom de fichier doit correspondre à une seule URL (pour éviter le cas décrit plus haut)
En mathématique, ce type de transformation est appelé bijection.
Une méthode pour transformer une URL en nom de fichier serait d’utiliser les numéros des caractères composant l’URL (dont le nom officiel est point de code).
Comme il s’agit d’une suite de valeurs numériques cela convient bien à des noms de fichiers. Malheureusement les noms de fichiers résultants sont plutôt longs (https://emojipedia.org/emoji/🐰/ est transformé en 68-74-74-70-73-3a-2f-2f-65-6d-6f-6a-69-70-65-64-69-61-2e-6f-72-67-2f-65-6d-6f-6a-69-2f-1f430-2f) ce qui n’est pas compatible avec tous les systèmes de fichiers.
Si vous voulez suivre cette approche une solution possible est de séparer la chaîne ainsi calculée en plusieurs tronçons, par exemple par blocs de 10 valeurs, et que chaque tronçon intermédiaire corresponde à un niveau de répertoire (dans notre exemple 68-74-74-70-73-3a-2f-2f-65-6d/6f-6a-69-70-65-64-69-61-2e-6f/72-67-2f-65-6d-6f-6a-69-2f-1f430/2f).
L’avantage de cette approche est que la transformation entre l’URL et le nom de fichier dépend uniquement de l’URL, mais sa mise en œuvre commence à être compliquée.
Une autre manière de mettre en place cette transformation est d’utiliser un dictionnaire, c’est-à-dire une source de données qui permette de stocker la correspondance entre URL en nom de fichier.
C’est un des usages des bases de données SQL :
on peut ainsi créer une table URL avec une colonne qui contient l’URL originale avec une clé d’unicité, et une colonne contenant un incrément automatique (aussi appelé séquence).
Lorsqu’on veut récupérer le nom de fichier correspondant à une URL, on commence par vérifier si cette URL est déjà dans la table, et sinon on l’insère.
La valeur de la colonne contenant l’incrément automatique fournit alors des identifiant adaptés à des fichiers, on aurait ainsi des fichiers 1, 2…
C’est comme si le nom de fichier était une clé étrangère vis-à-vis de cette table.
Sans utiliser de système de base de donnée externe, on peut utiliser une structure en mémoire, par exemple un Hash dont les clés seraient les URLs, ce qui assure l’unicité. Pour générer les valeurs de noms de fichiers, on peut utiliser le nombres d’entrées dans ce Hash, il s’agit d’une sorte d’incrément naturel :
KNOWN_URLS = {}
url = 'https://emojipedia.org/emoji/🐰/'
if KNOWN_URLS.key?(url)
file_name = KNOWN_URLS[absolute_url]
else
file_name = KNOWN_URLS.length
KNOWN_URLS[url] = file_name
endUtiliser une structure en mémoire convient très bien tant que le site à scraper ne contient pas des millions de pages, au delà il serait peut-être intéressant d’utiliser une base de donnée externe.
Télécharger une page et ses dépendances (pour de vrai)
Maintenant qu’on sait comment transformer une URL en nom de fichier, on peut s’intéresser au téléchargement proprement dit.
Pour télécharger les dépendances externes d’une page, le mécanisme est le suivant :
-
Identifier la liste des dépendances
-
Pour chaque dépendance
-
Si elle n’a pas déjà été téléchargée, la télécharger et la stocker sous le nom calculé en utilisant la méthode décrite plus haut
-
Modifier le HTML de la page pour remplacer l’URL de la dépendance par le chemin du fichier
-
Pour identifier la liste des dépendances, il faut parcourir le HTML. Pour cela la bibliothèque Ruby la plus utilisée est Nokogiri, elle sait parser du HTML et du XML et fournit ensuite une interface permettant de requêter et de modifier le contenu.
La première étape est de parser le contenu du HTML que l’on reçoit, et de préparer le fait que la sauvegarde va se faire dans un sous-répertoire pour éviter de mélanger le site avec le scraper.
Comme l’objectif est de scraper le magazine ACM Queue, j’ai aussi remplacé l’URL.
#!/usr/bin/env ruby
require 'net/http'
require 'fileutils'
require 'addressable'
INITIAL_URL = 'https://queue.acm.org'
TARGET_DIRECTORY = 'download'
# Supprime le répertoire de destination s'il existe et le recréé
if File.exists?(TARGET_DIRECTORY)
puts "Supprime [#{TARGET_DIRECTORY}]"
FileUtils.remove_entry_secure(TARGET_DIRECTORY)
end
puts "Créé [#{TARGET_DIRECTORY}]"
Dir.mkdir(TARGET_DIRECTORY)
puts "Télécharge [#{INITIAL_URL}]"
parsed_url = Addressable::URI.parse(INITIAL_URL)
response = Net::HTTP.get(parsed_url)
IO.write(File.join(TARGET_DIRECTORY, 'index.html'), response)Mais, quand on essaie d’ouvrir le fichier download/index.html résultant :
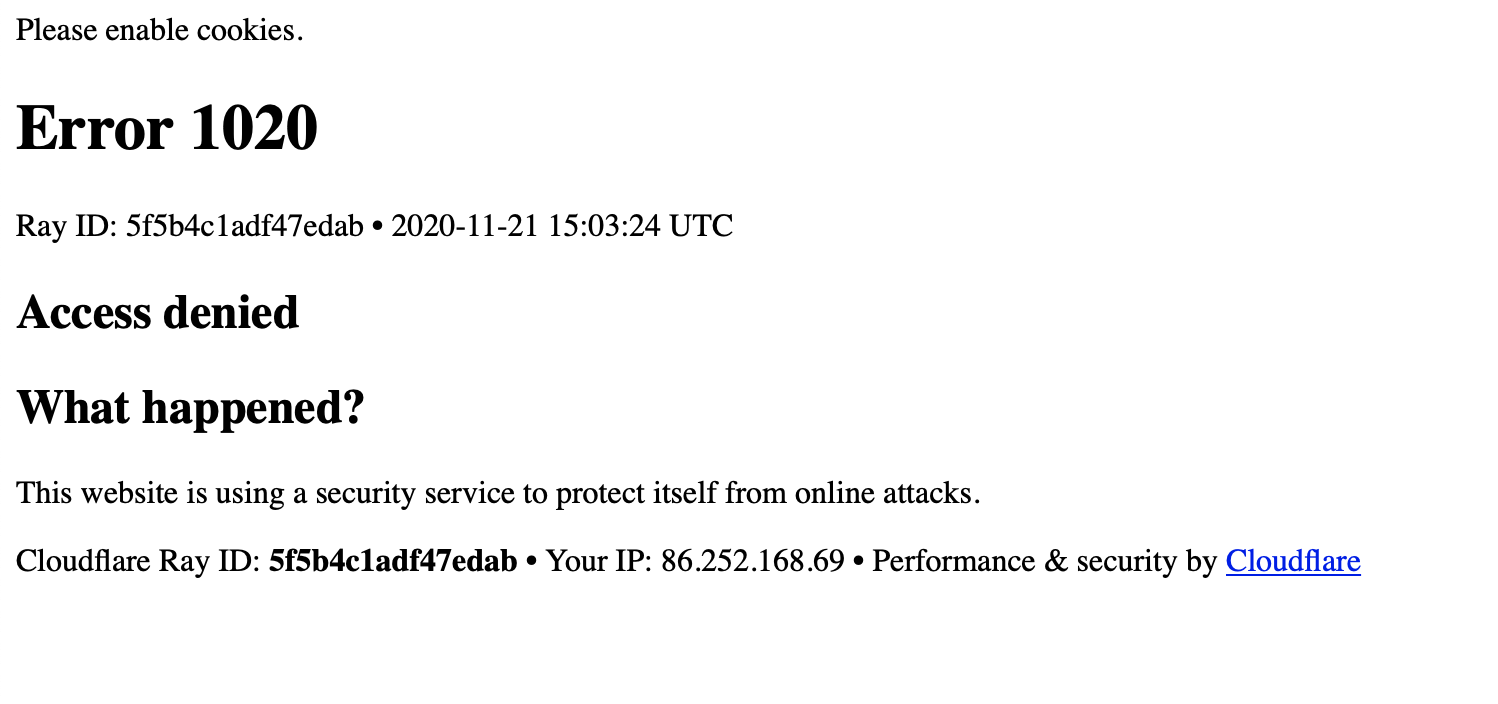
Pas de panique : il s’agit d’un mécanisme rudimentaire pour bloquer les robots.
Quand ce genre de choses arrive, il vaut mieux faire deux choses :
-
utiliser une bibliothèque HTTP qui a un comportement plus proche de celui des navigateurs
-
fournir une en-tête User-Agent pour accentuer la ressemblance avec un navigateur.
Si vous avez l’habitude d’utiliser une des bibliothèques HTTP qui est faite pour des appels REST, elle risque d’avoir le même problème, car une API REST n’a pas vocation à bloquer les clients qui ne sont pas des navigateurs.
Je vais passer de Net::HTTP à la bibliothèque Curb qui fournit une API Ruby au dessus de la bibliothèque libcurl, que vous connaissez peut-être à travers la commande curl utilisée pour faire des téléchargement depuis la ligne de commande.
puts "Télécharge [#{INITIAL_URL}]"
parsed_url = Addressable::URI.parse(INITIAL_URL)
response = Curl.get(parsed_url) do |http|
# Je suis un navigateur web !
http.headers['User-Agent'] =
'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/81.0'
end
IO.write(File.join(TARGET_DIRECTORY, 'index.html'), response.body_str)
Et ça fonctionne !

Le HTML est là, même si pour le moment sans CSS ni image.
Si vous allez jeter un œil au fichier HTML, une petite surprise vous attend :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<script type="text/javascript">
/* <![CDATA[ */_cf_loadingtexthtml="<img alt=' '
src='/cf_scripts/scripts/ajax/resources/cf/images/loading.gif'/>";En effet le contenu n’est pas au format HTML mais au format XHTML. Il s’agit à peu près d’une version XML de HTML4, créé par le W3C à l’époque où le XML était à la monde. Les deux avantages de cette approche étaient de pouvoir utiliser des outils XML pour pouvoir publier des sites (ce qui permettait notamment d’avoir la même chaîne de publication pour les livres que pour le contenu web) et de pouvoir utiliser des parsers XML, plus performants que les parsers HTML (cela prend son sens quand on se souvient des téléphones mobiles disponibles dans les années 2000). La vague du XML sur le web a été stoppée lorsqu’Apple, Mozilla et Opera ont décidé de monter un putsch contre le W3C en créant leur propre instance et leur propre format qui a abouti au HTML5.
Pour le scraper cela n’a aucune conséquence car Nokogiri traite le HTML et le XHTML de la même manière.
Je commence par déplacer le code de téléchargement dans une méthode séparée, car je vais en avoir besoin pour les ressources externes :
# @param [Addressable::URI] url
# @return [String]
def fetch_content(url)
response = Curl.get(url) do |http|
# Je suis un navigateur web !
http.headers['User-Agent'] =
'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/81.0'
end
response.body_str
endEnsuite je vais commencer par récupérer les images.
Le code suit exactement les étapes décrites plus haut, pour commencer je ne vais pas tenter de factoriser de code.
Pour la recherche dans le HTML, Nokogiri propose une méthode .css qui permet d’utiliser la syntaxe CSS :
puts "Télécharge [#{INITIAL_URL}]"
parsed_url = Addressable::URI.parse(INITIAL_URL)
doc = Nokogiri::HTML(fetch_content(parsed_url))
KNOWN_URLS = {}
# Localise les éléments img avec un attribut src
doc.css('img[src]').each do |image|
image_src = image['src']
# Assure d'avoir une URL absolue en combinant l'adresse de l'image
# avec celle de la page si l'image a une adresse relative,
# par exemple http://exemple.com + lapin.png = http://exemple.com/lapin.png
# si l'image a déjà une adresse absolue alors utilise celle là
# Addressable::URI#normalize essaie de corriger les URls incorrectes,
# par exemple celles qui contiennent des espace
image_url = parsed_url.join(image_src).normalize
if KNOWN_URLS.key?(image_url.to_s)
image_file_name = KNOWN_URLS[image_url.to_s]
else
puts "Télécharge [#{image_url}]"
image_file_name = KNOWN_URLS.length.to_s
KNOWN_URLS[image_url.to_s] = image_file_name
image_file_path = File.join(TARGET_DIRECTORY, image_file_name)
IO.write(
image_file_path,
fetch_content(image_url)
)
end
# Remplace l'URL d'origine par le nom du fichier
image['src'] = image_file_name
end
IO.write(File.join(TARGET_DIRECTORY, 'index.html'), doc.to_html)En lançant le script, les fichiers images sont bien crées :
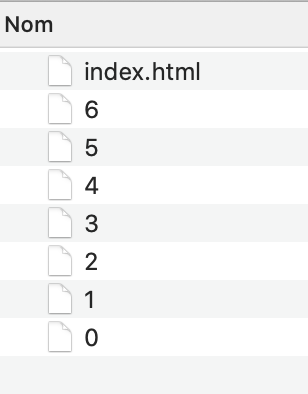
Elles sont bien remplacées dans le HTML :
<a href="index.cfm"><img src="0"></a>
<br>
<a href="whyjoinacm.cfm"><img src="1" border="0" style="clear:both;"></a>Et quand on visualise le fichier, les images s’affichent bien :

Par contre stocker les images dans des fichiers sans extension rend moins pratique l’exploration des résultats si on veut par exemple parcourir les fichiers.
Il est possible de récupérer les extension depuis les URLs et cela fonctionne plutôt bien pour les images.
Malheureusement ça n’est pas toujours le cas pour les fichiers générés dynamiquement comme les documents HTML ou XML.
Par conséquent il vaut mieux s’appuyer sur la déclaration de Content-Type qu’on trouve dans les entête de réponse.
La bibliothèque mime-types permet de déduire l’extension qui correspond à un certain type de contenu.
Je vais modifier la méthode fetch_content pour qu’elle renvoie l’extension à utiliser en même temps que le contenu téléchargé.
# @param [Addressable::URI] url
# @return [Hash] contient un :body et une :extension
def fetch_content(url)
response = Curl.get(url) do |http|
# Je suis un navigateur web !
http.headers['User-Agent'] =
'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/81.0'
end
extension = MIME::Types[response.content_type].first.preferred_extension
{
body: response.body_str,
extension: extension
}
endEt je vais m’en servir pour le nom des fichiers.
puts "Télécharge [#{image_url}]"
content = fetch_content(image_url)
image_file_name = "#{KNOWN_URLS.length}.#{content[:extension]}"
KNOWN_URLS[image_url.to_s] = image_file_name
image_file_path = File.join(TARGET_DIRECTORY, image_file_name)
IO.write(
image_file_path,
content[:body]
)
Les fichiers avec extension sont du coup bien reconnu par le système qui affiche les miniatures.
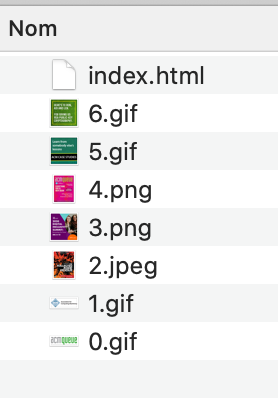
Reste à faire de même pour les feuilles CSS et le JavaScript. Ce qui donne l’occasion de factoriser un peu le code en extrayant le code de traitement d’une ressource dans une méthode scrape_resource.
Par courtoisie pour éviter de trop solliciter le serveur et potentiellement de se faire bloquer, je vais mettre une seconde d’attente après chaque téléchargement.
puts "Télécharge [#{INITIAL_URL}]"
parsed_initial_url = Addressable::URI.parse(INITIAL_URL)
doc = Nokogiri::HTML(fetch_content(parsed_initial_url)[:body])
KNOWN_URLS = {}
# @param [Addressable::URI] html_page_url
# @param [String] resource_url
# @return [String]
def scrape_resource(html_page_url, resource_url)
# Assure d'avoir une URL absolue en combinant l'adresse de la resource
# avec celle de la page
absolute_url = html_page_url.join(resource_url).normalize
puts "Vérifie la ressource [#{absolute_url}]"
if KNOWN_URLS.key?(absolute_url.to_s)
KNOWN_URLS[absolute_url.to_s]
else
puts "Télécharge [#{absolute_url}]"
content = fetch_content(absolute_url)
file_name = "#{KNOWN_URLS.length}.#{content[:extension]}"
target_file_path = File.join(TARGET_DIRECTORY, file_name)
IO.write(target_file_path, content[:body])
KNOWN_URLS[absolute_url] = file_name
# Attendre un peu
sleep(1)
file_name
end
end
doc.css('img[src]').each do |image|
image['src'] = scrape_resource(parsed_initial_url, image['src'])
end
doc.css('link[rel=stylesheet][href]').each do |link|
link['href'] = scrape_resource(parsed_initial_url, link['href'])
end
doc.css('script[src]').each do |script|
script['src'] = scrape_resource(parsed_initial_url, script['src'])
end
IO.write(File.join(TARGET_DIRECTORY, 'index.html'), doc.to_html)Et voilà :

Télécharger le reste du site
Pour récupérer l’ensemble du site, il va s’agir d’étendre le comportement actuel en l’étendant aux pages.
Lors du traitement d’une page, en plus des images, des feuilles de styles et des scripts, il va falloir chercher les liens. Si la cible du lien n’est pas encore connu, il faut le télécharger, et s’il s’agit d’une page HTML, il faut la traiter à son tour.
Ainsi de lien en lien, on devrait petit à petit parcourir l’ensemble du contenu du site.
La conception du parcours des liens est intéressante. Pour traiter une image il suffit de la télécharger et de la stocker sur disque en sauvegardant la relation entre son URL et le chemin du fichier où elle est stockée.
Mais lorsqu’un lien pointe vers une page HTML, cette page doit elle-même être traitée en remplaçant les URLs qu’elle contient vers les chemins des fichiers, après éventuellement les avoir sauvegardé.
Si une page HTML A référence une page HTML B, pour traiter la page A j’ai besoin d’avoir le nom du fichier où B sera sauvegardée. Si pour sauvegarder B je dois la traiter et donc parcourir ses liens, et que B a un lien vers une page C, j’ai besoin d’avoir le nom du fichier où C sera sauvegardée. Si pour sauvegarder C je dois la traiter…
Bref on se retrouve avec un genre de fonctionnement récursif, où on aurait besoin de parcourir l’ensemble du site une page après l’autre pour pouvoir ensuite à rebours sauvegarder les différentes pages : quand j’ai terminé de traiter C je peux la sauvegarder, et donc terminer de traiter B et la sauvegarder, et donc traiter A et la sauvegarder.
Les choses sont en fait plus compliquées que cela car les liens entre pages forment souvent des cycles. Par exemple si la page A est la page de sommaire du site, il y a des chances que toutes les pages vers lesquelles A pointe pointent à leur tour vers elle. Donc pour traiter A il y a besoin d’avoir traité B mais pour traiter B il y a besoin d’avoir traité A.
(╯°□°)╯︵ ┻━┻
La solution est une approche en deux passes en séparant d’une part ce qu’il est nécessaire de faire pour transformer les URLs des pages en lien vers des fichiers locaux, et d’autre part le fait de traiter ces pages :
-
On commence par télécharger et sauvegarder les cible des différents liens sans les traiter, afin de vérifier si leur contenu est au format HTML et d’obtenir les chemins des fichiers correspondant, ce qui permet de finir de traiter A.
-
Ensuite pour chaque cible de lien non encore traité, on relit le contenu qui a été sauvegardé sur disque, on le traite (en téléchargeant possiblement les autres pages vers lesquelles il pointe), puis on écrase le fichier avec la version traitée, c’est-à-dire avec les URLs des images, script, feuilles de styles et des liens qui pointent désormais vers leurs fichiers.
En parcourant le site, le script conservera une liste de page HTML déjà sauvegardées mais pas encore traitées. Lors du traitement d’une page, on pourra découvrir de nouveaux liens vers d’autres pages qui seront à traiter à leur tour et ainsi de suite.
Lorsque cette liste sera vide et donc toutes les pages traitées, cela signifiera que tout le site aura été parcouru.
La première étape est d’extraire la partie de scrape_resource qui s’occupe de sauvegarder un contenu dans un fichier dans une méthode séparée, afin de pouvoir l’utiliser directement.
# @param [Addressable::URI] html_page_url
# @param [String] resource_url
# @return [String] le nom du fichier
def scrape_resource(html_page_url, resource_url)
# Assure d'avoir une URL absolue en combinant l'adresse de la resource
# avec celle de la page
absolute_url = html_page_url.join(resource_url).normalize
puts "Vérifie la ressource [#{absolute_url}]"
if KNOWN_URLS.key?(absolute_url.to_s)
KNOWN_URLS[absolute_url.to_s]
else
puts "Télécharge [#{absolute_url}]"
content = fetch_content(absolute_url)
save_content(absolute_url, content[:extension], content[:body])
end
end
# @param [Addressable::URI] url
# @param [String] extension
# @param [String] content
# @return [String] le nom du fichier
def save_content(url, extension, content)
file_name = "#{KNOWN_URLS.length}.#{extension}"
target_file_path = File.join(TARGET_DIRECTORY, file_name)
IO.write(target_file_path, content)
KNOWN_URLS[url.to_s] = file_name
# Attendre un peu
sleep(1)
file_name
end
Ensuite la méthode scrape_link, va me permettre de traiter les liens de la même manière que scrape_resource pour les autres types d’URL. PAGES_TO_PROCESS va contenir les pages qui restent à traiter, j’en fait un Set pour avoir un dedoublonnage.
require 'set'
PAGES_TO_PROCESS = Set.new
# @param [String] current_page_url
# @param [String] resource_url
# @return [String]
def scrape_link(current_page_url, resource_url)
absolute_url = current_page_url.join(resource_url).normalize
# Traite seulement les liens qui sont sur le même nom d'hôte
# On peut également filtrer les adresses des pages
# dont on sait qu'elles ne nous intéressent pas
if PARSED_INITIAL_URL.host == absolute_url.host
puts "Lien interne trouvé [#{absolute_url}]"
unless KNOWN_URLS.key?(absolute_url.to_s)
puts "Nouveau lien interne [#{absolute_url}]"
content = fetch_content(absolute_url)
save_content(absolute_url, content[:extension], content[:body])
if content[:extension] == 'html'
puts "Nouvelle page à traiter [#{absolute_url}]"
PAGES_TO_PROCESS.add(absolute_url)
end
end
KNOWN_URLS[absolute_url.to_s]
else
puts "Lien externe trouvé [#{absolute_url}]"
absolute_url.to_s
end
endLa méthode scrape_link est typiquement une méthode qui sera modifiée en fonction du contenu à scraper.
On pourra par exemple exclure certaines URLs, exporter certaines informations dans un fichier ou une base de données séparées.
Les fonctionnements de scrape_link et celui de scrape_resource se ressemblent (vérifier si un contenu est déjà dans la liste, et sinon le télécharger) et on pourrait être tenté de les factoriser.
Mais scrape_link est suffisamment différent pour que ça ne soit pas une bonne idée car le mélange des deux perdrait en lisibilité.
Pour finir il manque la boucle de traitement des pages qui va être chargé de vider PAGES_TO_PROCESS.
Pour initialiser la boucle, PAGES_TO_PROCESS est remplis avec la page initiale qui doit auparavant être sauvegardée.
PARSED_INITIAL_URL = Addressable::URI.parse(INITIAL_URL)
# Initialise PAGES_TO_PROCESS
content = fetch_content(PARSED_INITIAL_URL)
save_content(PARSED_INITIAL_URL, content[:extension], content[:body])
PAGES_TO_PROCESS.add(PARSED_INITIAL_URL)
until PAGES_TO_PROCESS.empty?
current_page_url = PAGES_TO_PROCESS.first
PAGES_TO_PROCESS.delete(current_page_url)
current_file_path = full_file_path(KNOWN_URLS[current_page_url.to_s])
puts "Traite [#{current_page_url}] [#{current_file_path}]"
doc = Nokogiri::HTML(IO.read(current_file_path))
images = doc.css('img[src]')
images.each.with_index do |image|
image['src'] = scrape_resource(current_page_url, image['src'])
end
css = doc.css('link[rel=stylesheet][href]')
css.each.with_index do |link|
link['href'] = scrape_resource(current_page_url, link['href'])
end
scripts = doc.css('script[src]')
scripts.each.with_index do |script|
script['src'] = scrape_resource(current_page_url, script['src'])
end
as = doc.css('a[href]')
as.each.with_index do |a|
a['href'] = scrape_link(current_page_url, a['href'])
end
IO.write(current_file_path, doc.to_html)
end
On peut vérifier le fonctionnement dans le log :
Supprime [download]
Créé [download]
Traite [https://queue.acm.org] [download/0.html]
Vérifie la ressource [https://queue.acm.org/img/acmqueue_logo.gif]
Télécharge [https://queue.acm.org/img/acmqueue_logo.gif]
Vérifie la ressource [https://queue.acm.org/img/logo_acm.gif]
Télécharge [https://queue.acm.org/img/logo_acm.gif]
…
Lien interne trouvé [https://queue.acm.org/index.cfm]
Nouveau lien interne [https://queue.acm.org/index.cfm]
Nouvelle page à traiter [https://queue.acm.org/index.cfm]
Lien interne trouvé [https://queue.acm.org/whyjoinacm.cfm]
Nouveau lien interne [https://queue.acm.org/whyjoinacm.cfm]
Nouvelle page à traiter [https://queue.acm.org/whyjoinacm.cfm]
Lien externe trouvé [https://www.acm.org/joinacm2?ref=queue]
Lien interne trouvé [https://queue.acm.org/whyjoinacm.cfm]
Lien interne trouvé [https://queue.acm.org/index.cfm]
…
Traite [https://queue.acm.org/index.cfm] [download/18.html]
Vérifie la ressource [https://queue.acm.org/img/acmqueue_logo.gif]
Vérifie la ressource [https://queue.acm.org/img/logo_acm.gif]
Vérifie la ressource [https://queue.acm.org/confimg/Kode_Vicious2.jpg]
Vérifie la ressource [https://queue.acm.org/confimg/2020VirtualWinterSummit125x125(002).png]Si vous laissez le script tourner suffisamment longtemps, il devrait parcourir tout le site et l’archiver, et vous aurez sur votre disque dur une version navigable complète.
Les fragments
Le script fonctionne, on y est presque ! Il reste encore deux choses à modifier.
La première est la gestion des fragments dans les liens.
Pour le moment, on vérifie si une page est déjà connue en vérifiant si son URL complète existe dans KNOWN_URLS.
La conséquence est que si une URL contient un fragment, par exemple https://queue.acm.org/detail.cfm?id=2000516#content-comments, elle est considérée comme une URL différente de https://queue.acm.org/detail.cfm?id=2000516, et sera donc archivée comme une page à part. Suivant que les autres pages ont un lien avec ou sans fragment le lien aboutira donc à des pages différentes.
La solution est donc de retirer les éventuels fragments des URLs avant de consulter le contenu de KNOWN_URLS.
Pour calculer une URL cible, il faut donc chercher le nom du fichier dans KNOWN_URLS en utilisant l’URL sans fragment, et ajouter le fragment au nom du fichier.
La modification concerne seulement la méthode scrape_link :
# @param [String] current_page_url
# @param [String] resource_url
# @return [String]
def scrape_link(current_page_url, resource_url)
absolute_url = current_page_url.join(resource_url).normalize
# Traite seulement les liens qui sont sur le même nom d'hôte
# On peut également filtrer les adresses des pages
# dont on sait qu'elles ne nous intéressent pas
if PARSED_INITIAL_URL.host == absolute_url.host
puts "Lien interne trouvé [#{absolute_url}]"
absolute_url_no_fragment = absolute_url.omit(:fragment)
unless KNOWN_URLS.key?(absolute_url_no_fragment.to_s)
puts "Nouveau lien interne [#{absolute_url_no_fragment}]"
content = fetch_content(absolute_url_no_fragment)
save_content(absolute_url_no_fragment, content[:extension], content[:body])
if content[:extension] == 'html'
puts "Nouvelle page à traiter [#{absolute_url_no_fragment}]"
PAGES_TO_PROCESS.add(absolute_url_no_fragment)
end
end
file = KNOWN_URLS[absolute_url_no_fragment.to_s]
# Remet le fragment en fin d'URL s'il y en a un
file_url = Addressable::URI.parse(file)
file_url.fragment = absolute_url.fragment
file_url.to_s
else
puts "Lien externe trouvé [#{absolute_url}]"
absolute_url.to_s
end
endReprise en cas d’erreur
La dernière choses à modifier est de mettre en place une capacité de reprise en cas d’erreur.
Il arrive qu’un site ait des erreurs, ou que votre connexion internet plante, ou vous aurez peut-être envie d’interrompre le process.
Et quand cela arrive, il serait dommage d’avoir à recommencer le scraping depuis le début.
Pour éviter cela, il faut sauvegarder l’état du scraping après chaque étape, et lors du démarrage du script vérifier s’il existe un état sauvegardé, et dans ce cas le charger et repartir de ce point.
L’état du scraping correspond à deux ensemble de données :
-
KNOWN_URLSqui est le dictionnaire qui fournit les noms de fichiers correspondant aux URLs -
PAGES_TO_PROCESSqui est la liste des pages qui restent à traiter
À chaque fois qu’on modifie l’une de ces deux données il faut donc la sauvegarder.
Je vais sauvegarder KNOWN_URLS dans un fichier known_urls.txt, en utilisant une ligne par entrée en séparant l’URL et le nom de fichier par un espace :
https://queue.acm.org 0.html
https://queue.acm.org/img/acmqueue_logo.gif 1.gif
https://queue.acm.org/img/logo_acm.gif 2.gif
https://queue.acm.org/confimg/Kode_Vicious2.jpg 3.jpeg
https://queue.acm.org/confimg/2020VirtualWinterSummit125x125(002).png 4.png
https://queue.acm.org/app/2020_09-10_lrg.png 5.png# @param [Addressable::URI] url
# @param [String] extension
# @param [String] content
# @return [String] le nom du fichier
def save_content(url, extension, content)
file_name = "#{KNOWN_URLS.length}.#{extension}"
target_file_path = File.join(TARGET_DIRECTORY, file_name)
IO.write(target_file_path, content)
KNOWN_URLS[url.to_s] = file_name
IO.write(KNOWN_URLS_FILE_NAME, KNOWN_URLS.to_a.map { |l| l.join(' ') }.join("\n"))
# Attendre un peu
sleep(1)
file_name
endEt voici le code qui gère le chargement au démarrage si le fichier est présent :
KNOWN_URLS_FILE_NAME = 'known_urls.txt'
# @return [Hash{String, String}]
def initial_known_urls
if File.exists?(KNOWN_URLS_FILE_NAME)
Hash.new(IO.readlines(KNOWN_URLS_FILE_NAME).map{ |l| l.split(' ')})
else
{}
end
end
KNOWN_URLS = initial_known_urlsPAGES_TO_PROCESS sera sauvegardé dans un fichier pages_to_process.txt, en utilisant une ligne par entrée :
https://queue.acm.org 0.html
https://queue.acm.org/img/acmqueue_logo.gif 1.gif
https://queue.acm.org/img/logo_acm.gif 2.gif
https://queue.acm.org/confimg/Kode_Vicious2.jpg 3.jpeg
https://queue.acm.org/confimg/2020VirtualWinterSummit125x125(002).png 4.png
https://queue.acm.org/app/2020_09-10_lrg.png 5.pnguntil PAGES_TO_PROCESS.empty?
current_page_url = PAGES_TO_PROCESS.first
PAGES_TO_PROCESS.delete(current_page_url)
IO.write(PAGES_TO_PROCESS_FILE_NAME, PAGES_TO_PROCESS.to_a.map { |u| u.to_s }.join("\n"))
Et voici le code qui gère le chargement au démarrage si le fichier est présent, s’il en l’est pas on initialise le contenu avec le contenu du l’URL d’entrée du site :
# @return [Set]
def initial_pages_to_process
if File.exists?(PAGES_TO_PROCESS_FILE_NAME)
Set.new + IO.readlines(PAGES_TO_PROCESS_FILE_NAME).map{|l| Addressable::URI.parse(l)}
else
content = fetch_content(PARSED_INITIAL_URL)
save_content(PARSED_INITIAL_URL, content[:extension], content[:body])
Set.new + [PARSED_INITIAL_URL]
end
end
PAGES_TO_PROCESS = initial_pages_to_processJ’ai choisi de ne pas mettre de gestion d’erreur dans le script, par exemple une reconnexion automatique en cas d’erreur. Si un site est particulièrement instable il peut être nécessaire d’en ajouter, mais par défaut je préfère laisser remonter les exception et donc laisser le scraper s’arrêter pour me permettre de faire le choix moi-même.
Conclusion
Et voilà : le scraper est terminé ! J’espère qu’il vous sera utile, si vous avez des questions vous pouvez me contacter et j’essaierai de vous aider.
Ci-dessous la version finale du script pour vous servir de base.
#!/usr/bin/env ruby
require 'fileutils'
require 'set'
require 'addressable'
require 'nokogiri'
require 'curl'
require 'mime/types'
INITIAL_URL = 'https://queue.acm.org'
TARGET_DIRECTORY = 'download'
KNOWN_URLS_FILE_NAME = 'known_urls.txt'
unless File.exists?(TARGET_DIRECTORY)
puts "Créé [#{TARGET_DIRECTORY}]"
Dir.mkdir(TARGET_DIRECTORY)
end
# @return [Hash{String, String}]
def initial_known_urls
if File.exists?(KNOWN_URLS_FILE_NAME)
Hash.new(IO.readlines(KNOWN_URLS_FILE_NAME).map{ |l| l.split(' ')})
else
{}
end
end
KNOWN_URLS = initial_known_urls
# @param [Addressable::URI] url
# @return [Hash] contient un :body et une :extension
def fetch_content(url)
response = Curl.get(url) do |http|
# Je suis un navigateur web !
http.headers['User-Agent'] =
'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/81.0'
end
extension = MIME::Types[response.content_type].first.preferred_extension
{
body: response.body_str,
extension: extension
}
end
# Retourne le chemin complet vers le fichier
# @param [String] file_name
# @return [String]
def full_file_path(file_name)
File.join(TARGET_DIRECTORY, file_name)
end
# @param [Addressable::URI] html_page_url
# @param [String] resource_url
# @return [String] le nom du fichier
def scrape_resource(html_page_url, resource_url)
# Assure d'avoir une URL absolue en combinant l'adresse de la resource
# avec celle de la page
absolute_url = html_page_url.join(resource_url).normalize
puts "Vérifie la ressource [#{absolute_url}]"
if KNOWN_URLS.key?(absolute_url.to_s)
KNOWN_URLS[absolute_url.to_s]
else
puts "Télécharge [#{absolute_url}]"
content = fetch_content(absolute_url)
save_content(absolute_url, content[:extension], content[:body])
end
end
# @param [Addressable::URI] url
# @param [String] extension
# @param [String] content
# @return [String] le nom du fichier
def save_content(url, extension, content)
file_name = "#{KNOWN_URLS.length}.#{extension}"
target_file_path = File.join(TARGET_DIRECTORY, file_name)
IO.write(target_file_path, content)
KNOWN_URLS[url.to_s] = file_name
IO.write(KNOWN_URLS_FILE_NAME, KNOWN_URLS.to_a.map { |l| l.join(' ') }.join("\n"))
# Attendre un peu
sleep(1)
file_name
end
PARSED_INITIAL_URL = Addressable::URI.parse(INITIAL_URL)
# @return [Set]
def initial_pages_to_process
if File.exists?(PAGES_TO_PROCESS_FILE_NAME)
Set.new + IO.readlines(PAGES_TO_PROCESS_FILE_NAME).map{|l| Addressable::URI.parse(l)}
else
content = fetch_content(PARSED_INITIAL_URL)
save_content(PARSED_INITIAL_URL, content[:extension], content[:body])
Set.new + [PARSED_INITIAL_URL]
end
end
PAGES_TO_PROCESS = initial_pages_to_process
# @param [String] current_page_url
# @param [String] resource_url
# @return [String]
def scrape_link(current_page_url, resource_url)
absolute_url = current_page_url.join(resource_url).normalize
# Traite seulement les liens qui sont sur le même nom d'hôte
# On peut également filtrer les adresses des pages
# dont on sait qu'elles ne nous intéressent pas
if PARSED_INITIAL_URL.host == absolute_url.host
puts "Lien interne trouvé [#{absolute_url}]"
absolute_url_no_fragment = absolute_url.omit(:fragment)
unless KNOWN_URLS.key?(absolute_url_no_fragment.to_s)
puts "Nouveau lien interne [#{absolute_url_no_fragment}]"
content = fetch_content(absolute_url_no_fragment)
save_content(absolute_url_no_fragment, content[:extension], content[:body])
if content[:extension] == 'html'
puts "Nouvelle page à traiter [#{absolute_url_no_fragment}]"
PAGES_TO_PROCESS.add(absolute_url_no_fragment)
end
end
file = KNOWN_URLS[absolute_url_no_fragment.to_s]
# Remet le fragment en fin d'URL s'il y en a un
file_url = Addressable::URI.parse(file)
file_url.fragment = absolute_url.fragment
file_url.to_s
else
puts "Lien externe trouvé [#{absolute_url}]"
absolute_url.to_s
end
end
PAGES_TO_PROCESS_FILE_NAME = 'pages_to_process.txt'
until PAGES_TO_PROCESS.empty?
current_page_url = PAGES_TO_PROCESS.first
PAGES_TO_PROCESS.delete(current_page_url)
IO.write(PAGES_TO_PROCESS_FILE_NAME, PAGES_TO_PROCESS.to_a.map { |u| u.to_s }.join("\n"))
current_file_path = full_file_path(KNOWN_URLS[current_page_url.to_s])
puts "Traite [#{current_page_url}] [#{current_file_path}]"
doc = Nokogiri::HTML(IO.read(current_file_path))
images = doc.css('img[src]')
images.each.with_index do |image|
image['src'] = scrape_resource(current_page_url, image['src'])
end
css = doc.css('link[rel=stylesheet][href]')
css.each.with_index do |link|
link['href'] = scrape_resource(current_page_url, link['href'])
end
scripts = doc.css('script[src]')
scripts.each.with_index do |script|
script['src'] = scrape_resource(current_page_url, script['src'])
end
as = doc.css('a[href]')
as.each.with_index do |a|
a['href'] = scrape_link(current_page_url, a['href'])
end
IO.write(current_file_path, doc.to_html)
end