MRuby-Zest: a scriptable audio GUI framework
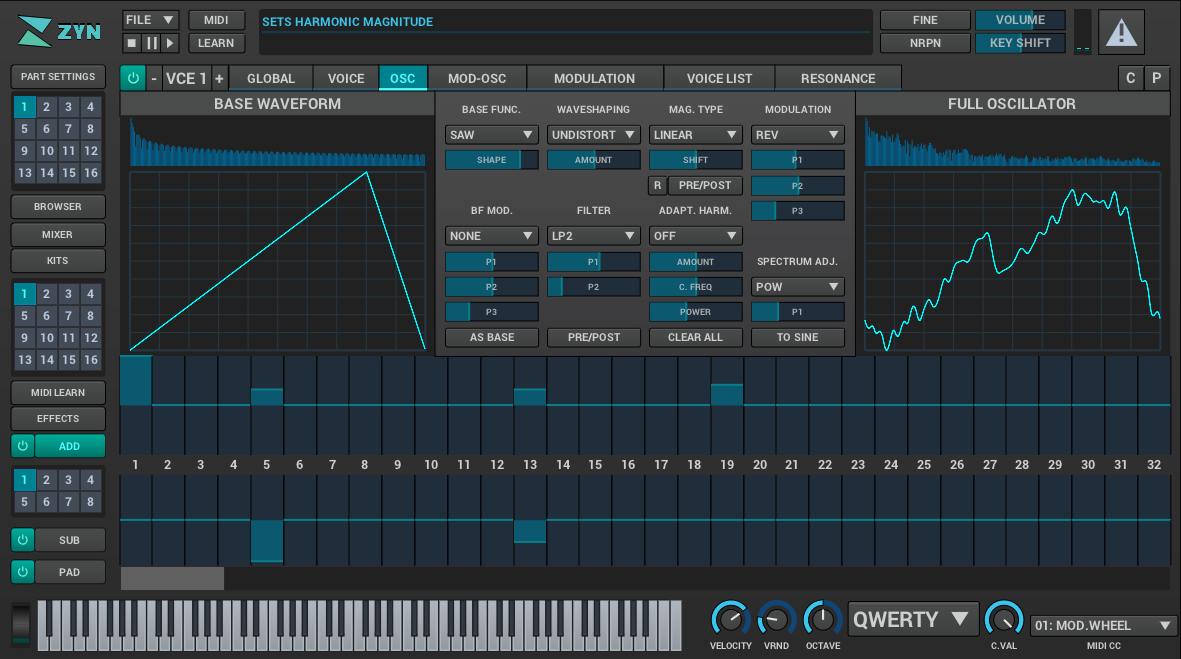
Audio tools face a set of uncommon user interface design and implementation challenges. These constraints make high quality interfaces within the open source realm particular difficult to execute on volunteer time. The challenges include producing a unique identity for the application, providing easy to use controls for the parameters of the application, and providing interesting ways to visualize the data within the application. Additionally, existing toolkits produce technical issues when embedding within plugin hosts. MRuby-Zest is a new toolkit that was build while the ZynAddSubFX user interface was rewritten. This toolkit possesses unique characteristics within open source toolkits which target the problems specific to audio applications.
Is your emotional intelligence authentic, or self-serving?
It’s possible to fake emotional intelligence. Similar to knockoffs of luxury watches or handbags, there are emotions and actions that look like the real thing but really aren’t. With the best of intentions, I’ve seen smart leaders charge into sensitive interactions armed with what they believed was a combination of deep empathy, attuned listening, and self-awareness but was, in fact, a way to serve their own emotional needs. It’s important to learn to spot these forgeries, especially if you’re the forger.
Mallet, a framework for creating proxies
On Friday 13th April 2018, I presented Mallet, a tools for building arbitrary proxies for arbitrary protocols, to the delegates at HackInTheBox Amsterdam. The slides are available here, and the video of the presentation is available on the HackInTheBox YouTube channel. This blog post aims to go into a bit more detail about how Mallet works, to give you a head start on creating your own proxies.
Mallet is built on the Netty Framework, which means that any existing ChannelHandler, Decoder or Encoder that works with Netty should work with Mallet. It also means that you are not limited to the protocols implemented by the Netty developers themselves, but can also make use of those implemented by users of the framework as well. For example, there is a COAP protocol implementation available, with a little searching.
A case study in not being a jerk in open source
Here’s a mailing list message written by Linus Torvalds, original author and maintainer of the Linux kernel. It’s unnecessarily mean. It also contains strong language, so probably don’t put this on text-to-speech unless you want people around you to hear profanity.
[…]
This is a much better email. It has 43% as many words, but loses none of the meaning. It’s still forceful and unambiguous. With fewer words, it’s easier for someone to absorb the core message about unthinking deference to standards.
It also doesn’t berate anyone, building a needlessly antagonistic culture around the project. Writing this email instead of the original email doesn’t require any extra work, and will save mileage on Linus' (or your) fingers besides.
If you were in the “I’m afraid that being nicer would hurt Linux” group, do you think that this email is worse? Is there any risk of a reader not understanding that the author disapproves of their reasoning and thinks that it’s dangerous?
Anatomy of a Linux DNS lookup - part I
Since I work a lot with clustered VMs, I’ve ended up spending a lot of time trying to figure out how DNS lookups work. I applied “fixes” to my problems from StackOverflow without really understanding why they work (or don’t work) for some time.
Eventually I got fed up with this and decided to figure out how it all hangs together. I couldn’t find a complete guide for this anywhere online, and talking to colleagues they didn’t know of any (or really what happens in detail)
So I’m writing the guide myself.
MySQL 8.0: new lock free, scalable WAL design
The Write Ahead Log (WAL) is one of the most important components of a database. All the changes to data files are logged in the WAL (called the redo log in InnoDB). This allows to postpone the moment when the modified pages are flushed to disk, still protecting from data losses.
The write intense workloads had performance limited by synchronization in which many user threads were involved, when writing to the redo log. This was especially visible when testing performance on servers with multiple CPU cores and fast storage devices, such as modern SSD disks.
We needed a new design that would address the problems faced by our customers and users today and also in the future. Tweaking the old design to achieve scalability was not an option any more. The new design also had to be flexible, so that we can extend it to do sharding and parallel writes in the future. With the new design we wanted to ensure that it would work with the existing APIs and most importantly not break the contract that the rest of InnoDB relies on. A challenging task under these constraints.